

今年4月に開催されたAI半導体最大手NVIDIAの年次イベントGTC2021。今年はオンライン開催ながらも、同社CEOのJensen Huang氏が例年通り基調講演を行った。ところが実はその講演の一部は、最新のAI技術で作成された3DCGアバターが本人に代わって喋っていた。同社がこのほど発表したもので、アバターであることに気づいた人はほとんどいなかったという。
以下が問題の基調講演。1時間2分41秒からの14秒間だけが、本人そっくりに3DCGで作成されたアバターによる講演だった。(以下の動画は、該当箇所から再生されるように設定されています)。
キッチンで話をしているHuang氏。この時点で既にアバター。


消えていく同氏のアバター。

バーチャル空間に登場した同氏。これはアバター。

キッチンに戻った同氏。今度は本人。違いがまったく分からない。

ではどのような技術を使ったのか、具体的に見ていこう。
担当者によると、これまでの3DCGは、動画データをベースに作るという手法が主流だった。ところが今回の取り組みでは、Huang氏の動画ではなく写真を使って、どの程度リアルな3DCGアバターを作れるのかということに挑戦したと言う。
まずは百台以上もの深度センサー付きカメラを360度配置した空間の中で、あらゆる角度から同氏の写真を撮った。

それらの写真をベースに3Dモデルを生成。
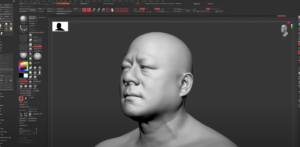
しゃべっているときの顔の表情は、audio2faceと呼ばれるAI技術で生成。音声データに合わせて、顔の表情が変化するという技術だ。
音声データと口元の動きは完全に一致したのだが、それでも不自然さが残った。そこで同社の研究開発チームの協力を得て、同チームが開発中のface video2videoと呼ばれる技術を使い、Huang氏の顔の写真を3Dモデル上に貼り付けた。
写真を貼り付けただけのモデルだと、頭を左右に動かしたときに、光が当たってる場所も同時に動いてしまい、見た感じが不自然になる。そこで光の向きを考慮して皮膚の明るさを変える技術を使ってモデルを修正。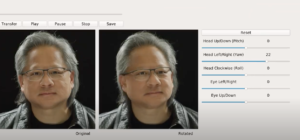
また身体部分も直立不動というわけにはいかない。息をするだけでも胸の筋肉は動くし、しゃべり始めると、いろいろな筋肉が動く。そこでaudia2gestureというAI技術を活用した。
まずは俳優にHuang氏の過去の講演動画を何本も見てもらい、同氏の動き方を学んでもらった。その上で俳優にセンサーを大量につけたモーション・キャプチャー・スーツを着てもらい、過去のHuang氏の講演を再現してもらった。そのデータを元に体の部分の3DCGを作成。
頭の部分の3DCGと合体させることで、Huang氏の3DCGアバターが完成した。あとは本人の講演の音声を入力すると、音声に合わせてアバターの口元が動き、表情や仕草が変化した。

私自身、今年もGTCの基調講演は記事を書くために何度も見返していた。だが、この部分のエフェクトは動画編集技術によるもので、同氏がアバターであることにはまったく気づかなかった。
テキストを本人の声で発声するAIも技術的には既に可能だし、今回の3DCGアバター技術と組み合わせることで、将来的にはスピーチの原稿を書くだけで、あとはアバターが講演してくれる、という時代になるかもしれない。
そうした技術をどんな用途に使えるのかは、まだ全然思いつかないけど。




湯川鶴章
AI新聞編集長
AI新聞編集長。米カリフォルニア州立大学サンフランシスコ校経済学部卒業。サンフランシスコの地元紙記者を経て、時事通信社米国法人に入社。シリコンバレーの黎明期から米国のハイテク産業を中心に取材を続ける。通算20年間の米国生活を終え2000年5月に帰国。時事通信編集委員を経て2010年独立。2017年12月から現職。主な著書に『人工知能、ロボット、人の心。』(2015年)、『次世代マーケティングプラットフォーム』(2007年)、『ネットは新聞を殺すのか』(2003年)などがある。趣味はヨガと瞑想。妻が美人なのが自慢。



