2025年はAIエージェント元年だと言われる。これから日本でもいろいろなAIエージェントが登場すると思われるが、AIの有力スタートアップ米Anthropicが早速「Building Effective Agents(効率的なエージェントの開発の仕方)」というブログ記事を公開している。この記事の中で紹介されている5つのエージェントのワークフローの形をベースに、どのようなエージェントが今後登場しそうなのかを考えてみたい。
AIエージェントとは一般的に「命令を受けて、その命令を達成するために何をすべきか、サブタスクを自分で考えて実行するシステム」というように定義されることが多い。何をすべきかを自分で計画し、自分で動く」というところがポイントだ。ところが今存在するエージェントの先行事例を見る限り、人間が何をすべきかサブタスクを考えるケースが多いようだ。
AnthropicもAIエージェントの定義を2つ用意している。1つは、ワークフロー型と呼ばれる定義で、「LLM(大規模言語モデル)やツールが事前に定義されたコードパスを通じて調整されるシステム」。もう一つは自律エージェント型と呼ばれる定義で、「LLMが自らのプロセスやツールの使用を動的に指揮し、タスクをどのように達成するかを自律的に制御するシステム」となっている。2つの定義の違いは、人間がタスクを計画するのかどうか、ということになる。ところがこの記事の中で紹介されているのは、ワークフロー型がほとんど。どうやらタスクの計画をAIに任せると、うまく機能しないことが多いようだ。
また記事の中で、エージェントを構築するのに便利なエージェントフレームワークを幾つか紹介しているが、こうしたノーコード、ローコードのフレームワークは簡単にエージェントが作れるので素人には便利な一方、「余分な抽象化レイヤーが作成され、基礎となるプロンプトと応答が分かりにくくなり、デバッグが難しくなる」と指摘している。Anthropicは、こうしたフレームワークを使わずに、LLMのAPI を直接使用することから始めることを推奨。フレームワークを使わずとも、数行のコードを書くだけでエージェントの構築が可能だとしている。
さてでは5つのワークフローの形を見てみよう。その前に5つのワークフローに共通する基本部品がある。その基本部品は、LLMを核にRetrieval(情報検索)、ツール、メモリなどの機能が追加されたものだ。
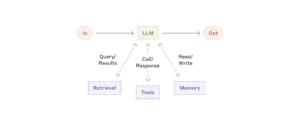
Retrieval(情報検索)は、外部のデータベースや知識ベースから必要な情報を検索してくる機能で、RAG(Retrieval-Augmented Generation)などの社内の情報の検索や、ネット検索などの機能のことだ。この機能のおかげで、社内の情報に加えて、医療や法律など専門的な質問に対し、信頼性の高い外部資料を参照して正確な回答を生成できたり、ニュース記事の要約や最新の研究成果を提供する際に、リアルタイムの情報を取得して回答の精度を向上させることができる。
ツールは、計算機能やAPI(Application Programming Interface、異なるソフトを連携させるプロトコル)経由で外部ツールを利用することのできる機能だ。LLMは言語モデルなので計算があまり得意ではない。そこで高度な数学の計算が可能やツールにアクセスして能力を補完するわけだ。またツールを使うことで、天気情報や株価など、特定のAPIから最新データを取得してユーザーに提供することも可能になる。
またメモリ機能を追加することで、ユーザーの好みや過去の選択を記憶し、より個別化された提案や回答を提供できたり、長期的なプロジェクトや複数回にわたる対話において、前回の内容を踏まえてスムーズな進行をサポートすることができるようになる。
この基本部品を5つのワークフローに搭載していくわけだ。それでは5つのワークフローを見てみよう。
1. プロンプトチェーン(Prompt Chaining)
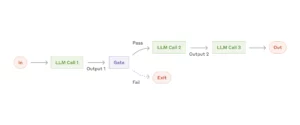
プロンプトチェーンは、複雑な案件を複数のステップに分割することで、精度を上げることのできるワークフローだ。例えば、多国籍市場向けの広告キャンペーンで、同じ内容を複数の言語で展開したい場合、まずは最初に「新製品の特徴を強調したキャッチーな宣伝文を作成してください」というプロンプトで日本語の宣伝文を生成させて、「この文章を英語に翻訳してください」というプロンプトで英語に翻訳させることができる。「宣伝文を英語で書いて」という一回のプロンプトで命令するよりも、より正確な英文が生成される可能性が高い。
別の例として、レポートや記事の作成時に、構成から執筆までのプロセスを体系的に進めたい場合、まずは「環境保護に関するレポートのアウトラインを作成してください」というプロンプトでアウトラインを生成。次に「このアウトラインが環境保護の最新トピックを網羅しているか確認してください」というプロンプトでアウトラインを検証。次に「以下のアウトラインに基づいて、各セクションの内容を詳しく書いてください: [確認済みのアウトライン]というプロンプトで本文の執筆してもらう、ということが可能になる。この場合は、「レポートを書いて」という一回のプロンプトで生成するよりも、アウトラインを確認することで趣旨により合った文章の生成が可能になる。
2. ルーター(Routing)
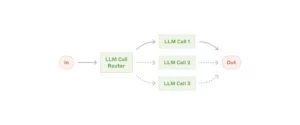
入力の種類を認識し、一番適切なLLMに振り分けるワークフロー。例えば、カスタマーサービスの問い合わせの内容を分析し、難易度や一般性に応じて「簡単/一般的な質問」と「難解/特殊な質問」に分類。簡単な質問の場合、軽量で高速な安価モデル(例: Claude 3.5 Haiku)に処理させる。難解な質問の場合は、使用料が割高な高性能なモデル(例: Claude 3.5 Sonnet)に処理させる。]
こうした分類により、使用コストの抑制や、応答速度の向上が図れる
3. 並列化(Parallelization)

タスクを分割して同時に走らせることで速度をあげたり、複数の視点を総合することで精度をあげたりできるワークフロー。例えば特定のコンテンツが不適切かどうかを評価する際、「暴力的な表現がないか確認して」「差別的な表現がないか確認して」「性的な表現がないか確認して」などといった複数のプロンプトを同時に走らせて、異なる側面を評価することができる。
4. 指揮者(Orchestrator-Worker)
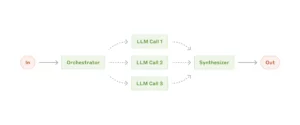
指揮者モデルがタスクを考えて、メンバーモデルに振り分け、それぞれの出してきた答えを統合する。並列化との違いは、並列化は人間がサブタスクを決めるが、指揮者型はAIがサブタスクを決めるところ。例えば、市場調査や競合分析などで、複数のウェブサイトやデータベースから情報を収集し、関連性のあるデータを分析する場合、指揮者は収集すべき情報の種類や対象となる情報源を指定し、各メンバーに収集・分析タスクを割り当てる。メンバーは、指定された情報源からデータを収集し、必要に応じてデータの前処理や初期分析を行う。複数のメンバーが同時にデータを取得することで、網羅的な情報収集が可能になり、収集されたデータを統合・分析することで、より正確で信頼性の高い結果が得られるようになる。
5. 評価と最適化(Evaluator-Optimizer)
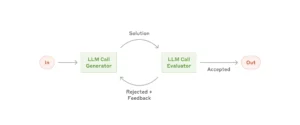
生成した内容を評価し、その結果をフィードバックするループを回し、精度を向上させる仕組み。明確な評価基準があるときに有効だ。例えば文学作品などを翻訳したい場合、文学作品の微妙なニュアンスや文化的背景を適切に反映する必要があるが、翻訳を担当するLLMは必ずしも初回の翻訳で全てを正確に訳せない。そこで、評価を行うLLMを活用してフィードバックループを回すことで、翻訳の品質を向上させることができる。
こうしたワークフローが、これまでのAIエージェントの成功例に見られる典型的なワークフローらしい。Anthropicのこのブログ記事は「過去に成功したケースの多くは、複雑なフレームワークや特殊なライブラリを使用せずに、シンプルで構成可能なパターンを使用している」「より複雑な処理が求められるときは、シンプルなワークフローのほうがいい。多くの場合は、検索とコンテキスト内の例を使用して単一の LLM 呼び出しを最適化するだけで十分だ」とアドバイスしている。
AIエージェントという言葉が流行り、自立型エージェント開発を謳うノーコードやローコードのフレームワークが登場しているが、何を実現したいのかを再確認し、最もシンプルな方法で実装するのが成功への近道のようだ。




湯川鶴章
AI新聞編集長
AI新聞編集長。米カリフォルニア州立大学サンフランシスコ校経済学部卒業。サンフランシスコの地元紙記者を経て、時事通信社米国法人に入社。シリコンバレーの黎明期から米国のハイテク産業を中心に取材を続ける。通算20年間の米国生活を終え2000年5月に帰国。時事通信編集委員を経て2010年独立。2017年12月から現職。主な著書に『人工知能、ロボット、人の心。』(2015年)、『次世代マーケティングプラットフォーム』(2007年)、『ネットは新聞を殺すのか』(2003年)などがある。趣味はヨガと瞑想。妻が美人なのが自慢。



