
中国のAIスタートアップDeepSeekが大きな話題を呼んでいる。同社の最新AIモデルDeepSeek R1が、OpenAIの論理的思考モデルのOpenAI o1(オーワンと発音)と同等の性能を出したのだ。しかも計算に必要な計算資源(高性能半導体の数と使用時間)が大幅に少なくて済むという。AI技術で中国は米国に追いついたのか。半導体やデータセンターに対する巨額投資は不要になったのだろうか。詳しく検証してみたい。
▼DeepSeek R1の概要
DeepSeekは、中国のヘッジファンドHigh-Flyerの共同創業者であるLiang Wenfeng氏が2023年5月、中国杭州市で創業したAIベンチャーだ。
DeepSeekは、2023年11月にプログラミング支援AIのDeepSeek Coderをリリースしてから、大規模言語モデルのDeepSeek、その後継バージョンの2,360億個のパラメータを持つDeepSeek V2と、矢継ぎ早にリリース。2024年12月にはDeepSeek V3をリリースし、2025年1月20日にDeepSeek R1をオープンソース形式でリリースした。
AIモデルの性能は、ベンチマークと呼ばれる各種テストで計測されるが、数学や科学、プログラミング、論理的思考などのベンチマークで、DeepSeek R1はOpenAI o1とほぼ同等の成績を叩き出している。
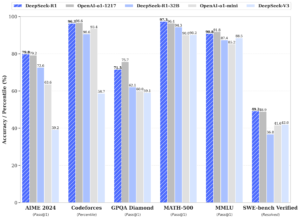
出典:https://pbs.twimg.com/media/GhvI3AoaAAAw-4z?format=png&name=4096×4096
R1はオープンソースの中でもMITライセンスと呼ばれるライセンス方式なので、そのまま自分のサーバーにダウンロードしてビジネスすることも可能だし、モデルのエッセンスだけを抜き出して軽量化したり変更を加えることも可能だ。
DeepSeekのサーバーにアクセスして利用する場合は利用料が必要だが、同じタスクのコストパフォーマンスを比較してみると、R1はo1の1/25のコストで同等のタスクをこなすことができる。さらには未リリースのOpenAI o3モデルよりもコスパが優れているという。
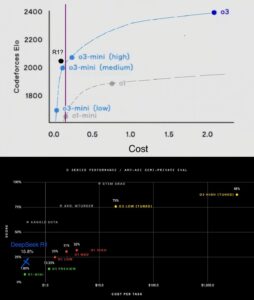
出典:https://pbs.twimg.com/media/GiRqO8eb0AA7Plb?format=jpg&name=large
なぜこのようなことが可能なのだろうか。R1の技術的な特徴を見てみよう。
▼R1の技術的な特徴
DeepSeek R1は、OpenAI o1と同様の「論理的思考モデル」「考えるAI」だと言われる。今までのAIがネット上のテキストデータを丸暗記して直感的に答えるAIだとすれば、「考えるAI」は「思考の連鎖(Chain of Thought)」ができるAI、つまり物事を段階的に考えることができるAIだ。
下の図にあるように「底辺が5cm、高さが2cmの三角形の面積を教えて」という質問に対して、今までのAIだと丸暗記したデータの中に同じ文言の質問と答えが含まれていれば、それを思い出して即答するし、もし含まれていないのであれば深く考えることなく、それっぽい答えを即答する。いわゆるハルシネーションを起こすわけだ。
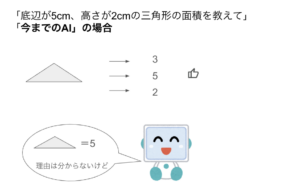
そうした即答に対して人間は正解であれば「いいね!」ボタンを押す。このフィードバックを受けてAIは「底辺が5cm、高さが2cmの三角形の面積を教えて」という問いに対しては、その理由は分からないが「5cm」と答えればいいんだな、と学習していく。
一方で「考えるAI」は、同じ質問を受けた場合に、どういう手順でこの質問の答えを出せばいいのかをいろいろ試行錯誤する。5と2を足したり、掛けたりするかもしれない。その試行錯誤の1つとして「三角形の公式」を丸暗記データの中から見つけ出し、その公式に数字を当てはめて計算する、という手順を試したところ、人間のユーザーから「いいね!」をもらえた。そこでAIは、こうした質問に関しては、公式を見つけ出して、数字を当てはめ、計算する、という手順(思考の連鎖)が有効なのだと学習する。
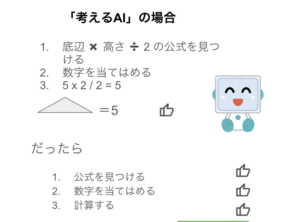
思考の連鎖のおかげで、ハルシネーションを起こす可能性が大きく減少する結果になる。
2024年9月にリリースされたOpenAI o1はこの思考の連鎖が可能なAIとしてAI研究を大きく進化させたのだが、DeepSeekはわずか3カ月でOpenAIに追いついてきたわけだ。
OpenAIはこの思考の連鎖のプロセスを明らかにしていないが、DeepSeekはこの仕組みを公開している。その特徴をmiLabというサイトでは「初期のファインチューニング(Cold Start)として少量の高品質データを用いた教師あり学習を行い、その後、GRPO(Group Relative Policy Optimization)という手法を用いた強化学習を適用することで、モデルの推論能力を大幅に向上させた」と説明している。
より噛み砕いた形で説明してみよう。
まずDeepSeekでは、R1の初期バージョンであるR1-zeroに、「底辺が5cm、高さが2cmの三角形の面積を教えて」のような問題を60万件を生成させている。その60万件の思考のプロセスや、たどり着いた答えの中から、正しいプロセスで正しい答えを出したケースをコンピューターを使って人間が選抜。間違ったプロセスや答えは修正した。そうしてできた20万件のデータを使ってR1を訓練。 正しい思考プロセスと答えを出したら「いいね!」、間違ってたら「よくない」と評価することで、AIが正しい思考プロセスを学んでいった。これが「少量の高品質データを用いた教師あり学習」のプロセスだ。
次にAIが自分で問題を出し、自分で思考のプロセスを考えて、自分で答えを出す方法で学習していった。これが強化学習と呼ばれる学習方法だ。これまでの強化学習では、思考プロセスと答えが正しいかを判断する別のAIモデルを使っていたが、R1は自分で自分の答えを評価する。しかも「正解 or 不正解」ではなく、「この答えはこっちより良い」という相対的評価の方法を使った。これがGRPO(Group Relative Policy Optimization)という手法だ。これだと評価用の別モデルを作る必要がないし、絶対評価ではなく相対評価なので追加の計算負荷が少なく、高速に学習できるわけだ。
▼エンジニアが驚き、投資家、政治家が驚いた
この誰もが思いつきそうなシンプルな手法で実際に効果が出たので、世界中のエンジニアが驚いたわけだ。
MicrosoftAI フロンティア研究室の主任研究員Dimitris Papailiopoulos氏は「最も驚いたのはエンジニアリングのシンプルさ。すべての論理的ステップを詳細に記述するのではなく、正確な答えを目標として高いレベルの有効性を維持しながら計算時間を大幅に短縮している」と語っている。
英AIコンサルティング会社DAIR.AIのElvis Saravia氏は「これは驚くべき、まったく予想外のことだ」と語り、Perplexity CEO 、Aravind Srinivas 氏は「This is insane!!!(すごすぎる!」「これから検索、エージェントに活用していきます!」と大絶賛している。
しかしもっと驚いたのは、投資家だった。大幅な効率化が可能になったのだから今までのような計算資源は不要になるかもしれない。高性能半導体もそれほど多くは必要でなくなる可能性がある。そう考えた投資家が多かったのだろう。高性能半導体のトップメーカーであるNVIDIAの株価は1日で17%も下落。時価総額が約6000億ドル(約92兆円)も減少した。これは、米国企業としては史上最大の下落幅だ。
また米国の政治家たちも驚いたに違いない。AI技術で先行する国は軍事力でも先行するようになると考えられているからだ。
▼AI技術で中国は米国に追いついたのか
米国の一部政治家が懸念しているように、中国は米国に追いついたのだろうか。OpenAI o1のリリースが2024年9月、DeepSeek R1のリリースが2025年1月だから、4カ月で追いついたことになる。以前は、中国のAIは米国より1年以上遅れていると言われていたので、その期間が短くなっていることは事実だ。しかしまだ4カ月の差がある。日進月歩のAI業界において4カ月は非常に大きな差だ。4カ月もあれば技術も業界勢力図も大きく変化する。なので、まだそこまで心配する必要はないのかもしれない。
またAIの技術開発で先頭を走るのと、2番手として追いかけるのとでは、全く異なる社風と資金力が必要になる。AIの技術開発と通常のIT業界の技術開発の違いについて、昨年6月にOpenAIに参画した製品担当責任者のKevin Weil氏は次のように語っている。
「OpenAIではコンピューターに何ができるかが2、3カ月ごとに突然変わる。コンピューターが、世界で誰も見たことのない新しい能力を突然身につけて、それをベースに製品作りを考えないといけない。
コンピューターが次にどんな能力を持つのかは、はっきりと分からない状態、かすかにその兆しが霧の中に見えてきたような状態で、次の製品作りを始めないといけない。これが、私がこれまでに経験してきたテック企業の製品作りと全然違うところだ」
OpenAIのCEOのSam Altman氏も次のように語っている。
「サイエンス(リサーチの結果)の言う通りに動かなければならないというのが他のテック企業との違いだと思う。次にどんなプロダクトを作るのかを決めるのは非常に難しい。AIがどんな能力を持つのかに関して我々の予測が当たることもあるが、多くの場合は予測が当たらないからだ。当たらないときはすべてを捨ててピボットするしかない。サイエンスの言う通りに動くしかなくて、サイエンスの言う通りに動くというのが我々の特徴だ」
次にAIにこのような機能を持たせようと研究開発するのではなく、どんな機能が実現するのか分からないが、とりあえず研究開発をし続けなければならないというわけだ。
できるかどうか分からないことを探求するのと、既にできることが証明されている技術を再現するのでは、容易さが全然違う。Altman氏は「他の人が見つけた方法をコピーして展開するのは、簡単なことだ」と語る。
ただOpenAIは困難な事に挑戦する社風だと言う。「われわれは、新しいパラダイムを次々と見つけようとしている。それがわれわれのしたいことでもあるし、それを製品化に結びつけるというのがわれわれが得意とするところでもある。それは大変な仕事だけど、それをするのが好きな社風といいうのが、OpenAIの強みだと思う」(2024年9月の開発者会議でのAltman氏の発言)。
できるかどうか分からないことを探求するための資金力と社風が、DeepSeekにもあるのだろうか。
▼DeepSeekの社風
DeepSeekのCEO、Liang Wenfeng(梁文鋒)氏の2024年7月のインタビューがThe China Academyというサイトに掲載されている。
どうやらDeepSeekは、基礎研究に注力する会社のようだ。「ほとんどの中国企業は基盤モデルとアプリケーションの両方を追求しています。なぜ DeepSeek は基盤モデルの研究にのみに注力しているのでしょうか?」という質問に対して次のように答えている。
「今最も重要なことはグローバルなイノベーションに参加することだと信じているからです。長年、中国企業は他国で開発された技術革新を活用し、アプリケーションを通じて収益化することに慣れていました。しかし、これは持続可能ではありません。今回、私たちの目標は短期的な利益ではなく、技術の最先端を前進させてエコシステムの成長を促進することです」
基盤モデルで勝負しようとすると、潤沢な資金を持っているトップ企業との資金競争に陥ってしまう。有力企業が基盤モデルの開発競争から次々と脱落していく中で、収益を重視する中国企業の考え方は真っ当だと思うのだが、この事に対してWenfeng氏は、「欠けているのは資本ではなく、効果的なイノベーションのために優秀な人材を組織化する自信と能力です」と言う。中国の老舗IT企業には世界での競争に勝とうという気概や自信がない、とでも言っているようだ。
DeepSeekが採用しているのは「トップクラスの大学を卒業したばかりの学生、博士課程の学生、そして数年の経験を持つ若い才能だけだ」と言う。「イノベーションには自信が必要であり、若者は自信を持っている傾向があります」「トップクラスの人材にとって最も魅力的なのは、世界で最も困難な課題を解決する機会です。実際、中国のトップクラスの人材は、ハードコアなイノベーションが稀で、ほとんど認められないため、過小評価されがちです。私たちは、彼らが切望するものを提供します」。
既存の中国のIT大手に入社すれば、アプリの開発部署に回される。しかし「トップクラスの人材」はアプリ開発では実力を出し切れない。「世界で最も困難な課題」であるAIの最先端基盤モデルを作るという機会を与えることで、DeepSeekにはトップ人材が集まる、というわけだ。
Wenfeng氏の思惑通りにトップ人材が集まれば、OpenAI同様の社風は作れるのかもしれない。
しかし資金はどうだろう。今は同氏が共同創業したヘッジファンドからの資金で運営しているようだが、それだけで今後もDeepSeekを運営できるのだろうか。
Wenfeng氏はどうやらエコシステムの構築を考えているようだ。「今は技術革新の時期だと考えています。長期的には、業界が当社の技術と成果を直接使用するエコシステムの構築を目指しています。他社が当社のモデルに基づいて B2B/B2C サービスを開発する一方で、当社は基礎研究に注力していきます」
この方針でベンチマークしているのがNVIDIAのようだ。NVIDIAの半導体は確かに最先端を走り続けているが、他社が追いつけないのは半導体そのものの技術だけではない。同社の半導体をよりよく活用するためのソフトなどがサードパーティーからいろいろ開発されている。それを利用するにはNVIDIAの半導体を使うしかない。エコシステムの真ん中にいるということがNVIDIAの最大の強みなわけだ。
そうしたエコシステムを確立するためには、「強いチームで次世代技術を追いかける必要があります。それが本当のNVIDIAの強さです。NVIDIAの半導体に秘密などありません」とWenfeng氏は言う。
多分に理想主義で、中国の先輩経営者からは意見されることがあるのかもしれない。しかしWenfeng氏は「すべての戦略は過去の産物。将来通用するとは限らない」と語る。ネット時代の勝ち筋はAI時代に通用しない。自分は自分の考えで進む。そう言っているようだ。
▼半導体輸出規制に効果はなかったのか
米中のAI開発競争に大きな影響を与えると見られているのが、半導体輸出規制だ。「中国に輸出が認められているNvidiaのGPUは最先端GPUの半分の速度だ」(DeepSeek元従業員、ノースウェスタン大学博士課程在籍の学生Zihan Wang氏)と言われる中で、どのようにしてDeepSeek R1を開発できたのだろうか。
Wang氏は「DeepSeek は、精度を大幅に犠牲にすることなく、メモリ使用量を削減し、計算を高速化する方法を見つけました。チームは、ハードウェアの課題をイノベーションの機会に変えることを楽しんでいます」と語る。
MIT Technology Reviewは「輸出規制が中国の AI 能力を弱めるのではなく、DeepSeek のようなスタートアップに、効率、リソースのプール、コラボレーションを優先する方法で革新を起こすよう促している」としているし、The Wire Chinaは「DeepSeek-R1 の登場により、皮肉な事実が明らかになった。短期的には進歩を妨げる制裁は、長期的にはイノベーションを促進することになっている」としている。
輸出規制は効果がないのだろうか。
実は、予想される制裁措置のずっと前に、Wenfeng氏が、現在中国への輸出が禁止されているタイプのNvidia A100チップを大量に購入したという情報がある。中国メディア36Krは、同社が1万個以上、AI研究コンサルタント会社SemiAnalysisは、少なくとも5万個は持っていると推定している。第3国ルートで取得したという噂もある。
またDeepSeekがOpenAIのデータを不正に入手した疑いが浮上し、現在MicrosoftとOpenAIが共同で調査を進めているという報道が出ている。
真意のほどはまだ明らかになっていないが、輸出規制が完全に無意味というわけではないだろうし、DeepSeekがOpenAIに追いつきそうなのであれば、米国政府はさらに何らかの手を打ってくる可能性がありそうだ。
▼大量の計算資源はもはや不要なのか
2024年9月の段階では、OpenAIのSam Altman氏は「高性能半導体を大量に購入することに注力した時期があったが、今はリサーチが重要なフェーズに入ってきた」と語っている。
一方で直近のX上の同氏の投稿では「これまで以上に計算資源が重要だと考えています」と語っている。
急速な進化が続く中で計算資源の重要性も変化し続けるのだろうが、NVIDIAのJensen Huang氏は、これまでの事前学習に加えて、事後学習、推論時にも計算資源を大量に投入することでAIモデルの性能が向上することが分かってきた、と語っている。
事前学習、事後学習について同氏は「事前学習は、学校で学ぶようなもの。事後学習は家庭教師にアドバイスをもらったり自習するようなもの」という比喩で説明している。事前学習に計算資源を投入することは、学校で学んでいるときに一生懸命考えるようなもの。事後学習は、自宅に帰って自分で勉強するようなもの。推論は、実際にテストを受けるようなもの。
これまでは学校で勉強する時だけ一生懸命頭を使っていたが、自宅で勉強するときも、実際にテストを受けているときも、一生懸命頭を使った方が成績がよくなる。事後学習、推論時にも計算資源を投入することの効果が見えてきたというわけだ。
事実、NVIDIAの収益の既に40%は、推論時の半導体利用が占めるようになっているという。さらに同氏は「思考の連鎖によって、推論からの収益が1万倍、いや10億倍の規模に達することになるんです。このことにまだ多くの人は気づいていません。これはまさに産業革命なのです」と語っている。
確かにAIは今年、AIエージェントになり、その場その場で思考するようになる。そしてAIエージェントは人型ロボットに搭載され、あらゆる職場に導入されるようになる。今後ますます多くの計算資源が必要になる可能性が大きい。
1月28日の終値が前日比8.8%高と大きく上昇、時価総額は約2600億ドル(約38兆円)回復した。多くの投資家がDeepSeek R1の脅威を過大評価していた事に気づき、冷静な見方が広まったのだろう。




湯川鶴章
AI新聞編集長
AI新聞編集長。米カリフォルニア州立大学サンフランシスコ校経済学部卒業。サンフランシスコの地元紙記者を経て、時事通信社米国法人に入社。シリコンバレーの黎明期から米国のハイテク産業を中心に取材を続ける。通算20年間の米国生活を終え2000年5月に帰国。時事通信編集委員を経て2010年独立。2017年12月から現職。主な著書に『人工知能、ロボット、人の心。』(2015年)、『次世代マーケティングプラットフォーム』(2007年)、『ネットは新聞を殺すのか』(2003年)などがある。趣味はヨガと瞑想。妻が美人なのが自慢。