
ChatGPTの人気がおさまりそうにない。多くの日本企業がChatGPTをどう事業に取り入れるのかを検討し始めたようだ。
企業の取り入れ方は、ChatGPTを全社員に解放することで社の生産性を上げようという社内向け用途と、顧客向けのチャットボットを開発するなど社外向け用途の2つに大別される。
今回の記事のテーマは、後者。顧客向けサービスにChatGPTなどのOpenAIの言語モデルをどう活用するのか、そのカスタマイズの方法について解説したい。
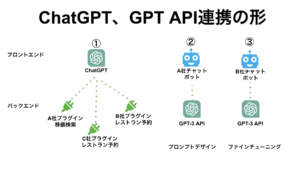
カスタマイズの方法は、大きく分けて3つ。1つはChatGPTにプラグインを提供する方法。2つ目は、よりよい回答を得るために質問を工夫するプロンプトデザインという方法。3つ目は、追加学習させてモデルを新しく作るファインチューニングという方法だ。下の図のように、プラグインはサービスの前面にChatGPTが出るイメージ。プロンプトデザインとファインチューニングは、一般企業のチャットボットが前面に出てGPT-3が裏方に回るイメージだ。
プラグインは、3月に発表されたばかりの機能で、ChatGPTに一般企業が機能やデータベースを提供できる機能。ChatGPTは、TwitterやFacebookなどとは比較にならないスピードで世界中のユーザーを獲得していった超人気チャットボット。Google検索の代わりにChatGPTで情報を収集しようという動きが広まっており、サードパーティにとってはChatGPTに機能やサービスを提供することで、自分の会社のサービスの知名度を上げたり利用者を増やすメリットがある。ちなみにプラグインが使われるたびに、プラグイン提供企業のサイトのスクリーンショットとURLがChatGPT画面に表示されるようになるという
一方でOpenAI側には、サードパーティの力を借りてChatGPTの機能を拡充できるというメリットがある。これまでChatGPTには、①高度な数学が苦手、②外国語にそれほど強くない、③最新の情報を持っていない、④うその情報が混ざる、などの欠点があった。プラグインの仕組みができ、サードパーティーのプラグインが増えることで、これらの欠点を克服できるようになるとみられている。
OpenAIによるプラグイン発表時には、レストラン予約サービスのOpentableや、食材配達サービスのInstacart、各種統計データや高度計算機能を持つWolframなど、8社のプラグインが同時発表された。今後いろいろな企業がプラグインを提供してくるものとみられているが、現時点でも次のようなことができると考えられている。
例えばユーザーがChatGPTに対して、好きな料理などを教えたあとで、次のように話しかけたとしよう。
「週末はすてきなレストランで彼女と夕食をともにしたい。平日の夕ご飯は自炊するので、レシピを考えておいて。ダイエット中なので、しっかりカロリーも計算してね。あとは食材の配達が夕食に間に合うように近くのスーパーに配達をお願いしておいてね」
こう命令しておくと、Opentableがレストランを予約し、Wolframがレシピを検索しカロリーを計算。Instacartが必要な食材を近くのスーパーに注文してくれるようになる。
ちょうどアプリストアという仕組みができたことで、スマートフォンが格段に便利になったように、プラグインという仕組みが理由で、ChatGPTが一気に使い勝手がよくなるとみられてる。
2つ目のカスタマイズ方法は、プロンプトデザイン。
プロンプトとは、言語AIに入力する質問や命令のこと。一方で出力された回答はコンプリーションと呼ばれる。
例えば自社のチャットボットをGPT-3にAPI(プログラム間の接続口)で接続している場合に、ユーザーからチャットボットに対して「スマホがフリーズしたんですが、どうすればいいですか」という質問がきたとしよう。この質問に加えて、「Q:スクリーンが固まった A:電源を切ってみて」「Q:画面が動かない A:電源を落としてみて」などといった過去の質疑応答の模範解答データをプロンプトに追加すれば、GPT-3はより正確な返答を返してくるようになる。
このようにプロンプトを工夫することをプロンプトデザインと呼ぶ。このカスタマイズ方法だと、ユーザーからの質問に合ったプロンプトを自動で追加する仕組みを作らなければならないし、GPT-3の使用料をOpenAIに支払わなければならない。
プロンプトに追加する例文が多ければ多いほどGPT-3はより適切な解答をしてくれるが、プロンプトが長くなれば使用料も高くなるし、反応も遅くなるというデメリットもある。
OpenAIの言語モデルのカスタマイズ方法の3つ目は、ファインチューニングと呼ばれる方法だ。
GPT-3のコピーを作り、それに過去の質疑応答のデータなどを追加学習させて、新たなモデルを作るという方法だ。プロンプトデザインの場合と違って、質疑応答の模範回答など学習データを好きなだけ用意して学習させることができるので、プロンプトデザインよりも的確な返答を出力することが可能になる。
大規模言語モデルを1から構築するには大量の学習データと数ヶ月間の学習期間が必要になると言われるが、GPT-3のコピーをベースに使うことで、数時間程度で学習させることが可能という。
またユーザーからの質問に回答例などのプロンプトを追加する必要がないので、返答の時間が短縮されるというメリットもある。
一方で、GPT-3のコピー作成や、学習データ集めと学習コストなどの初期コストがかかる上、できたモデルのホスティングコストがかかる。
それぞれ一長一短なので、自社に合った方法を選択する必要がありそうだ。




湯川鶴章
AI新聞編集長
AI新聞編集長。米カリフォルニア州立大学サンフランシスコ校経済学部卒業。サンフランシスコの地元紙記者を経て、時事通信社米国法人に入社。シリコンバレーの黎明期から米国のハイテク産業を中心に取材を続ける。通算20年間の米国生活を終え2000年5月に帰国。時事通信編集委員を経て2010年独立。2017年12月から現職。主な著書に『人工知能、ロボット、人の心。』(2015年)、『次世代マーケティングプラットフォーム』(2007年)、『ネットは新聞を殺すのか』(2003年)などがある。趣味はヨガと瞑想。妻が美人なのが自慢。